关于3D处理的MMX(多媒体增强指令集)技术
目录:
- 执行概要
- 读者对象
- 3D图形处理流程
- 光栅处理
- 像素点色深的转换:8位,16位,24位
- 系统带宽考虑事项
- 内存访问最优化
- 性能预测
- 软加速与硬加速
- 结束语
- 附录
虚构与现实
MMX技术 适用于几何学?
3D术语表以及有用的链接
一、执行概要
INTEL公司的MMX处理器能成倍增加并行处理的整形数据,一次能处理64位。与一次最多处理32位的纯粹的INTEL结构代码相比,它能加快处理3D图像中的像素点。因此,MMX技术可提供更高层次的速度和更高质量的图像。
虽然MMX技术也能适用于8位像素点的处理,但他最适合于16位或24位的彩色处理。INTEL及其它一些开发者已经使用MMX技术编写了3D处理代码。在alpha混合,Gourand阴影,Z-缓冲,像素点色深转化,映像复制,双线性过滤,结构映射,程序结构化等方面,MMX技术已体现出了优越性。MMX技术的运算在处理16位色或24位色时,可以加快1到3倍。但在处理8位色时,只能提高速度30%或更少。这些加速来自于:
- 并行的SIMD(单指令多数据)处理
- 通过MOVQ指令的8字节存储
- “饱和”算法:这使得能通过加上一个小数(0x010101)来增亮一个白点(在24位的RGB中用FFFFFF表示)从而得到另一种白色,而不是黑色(000000)。
- 多重加法指令(PMADD)在一个简单时钟周期中执行。
- 封装好的比较运算(PCMP),这使得能允许从许多运算法则中移出数据相关的分支为了更好的执行,使用MMX技术的SW设计者必须小心地注意与系统的带宽相和谐。PCI总线和图形芯片的存在阻碍了与显卡之间的数据吞吐能力,
使写入的速度降低到大约80MB/S。对于读来说,会更慢。同样,当前的主存系统流量一般来说要比所能承受的带宽慢160MB/S。
然而,CPU外带的缓存的速度是这种速度的2倍 。而且,内部缓存的速度更是主存速度的10倍。
代码编写者应该尽量使他们所需的数据留在缓存中。 而且,应避免从显卡中读数据(通过PCI总线)。即使新的PCI总线能显著地加快从CPU中读写数据的速度,也应避免从显存中读数据。AGP总线能通过图形集成电路和CPU更便利地以高带宽共享
主存区的内容。
建造一个为MMX技术服务的3D应用软件就像建一个3D硬件加速器一样
,都是使用16位或24位的格式。在一些情况下,软件处理器比直接的3D硬件运行得快,而且显然更灵活。在其他的一些情况下
,使用软件能使得前景事物与特殊效果结合的更紧,而后景处理则交给硬件完成。
硬 件增加了在建立注册表和同步器上的某些费用,
也理所当然地拥有了到显存更高的带宽。因为存储器和加速器都在PCI总线(其它总线也一样)的同一端。
二、读者对象
这篇文章是为编程者和技术管理员而写的。同时也是作为关于3D图形处理的MMX技术的一个概述。它提供了一些最有效的策略和执行上的权衡的线索。
与其写一些客户代码,编程者们更愿意使用MMX技术中的3D
API库。比如Mcrosoft的Direct3D,
Criterion的Rdnderware,Argonaut的Brender。但这篇文章对光栅处理给出了自定译码的深入研究。我们假设读者已经对3D图形技术的概念和术语十分熟悉。
三、3D图形处理流程
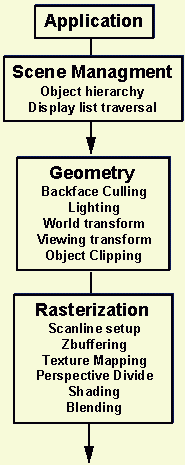 在插图1中可以看到3D图像处理流程是由一个应用程序来控制的。通常是通过通知一个API函数来实现的。景象管理在这个应用中可能是完整的,也可能成为API函数下的3D流程的一部分。景象管理传递给3D管道处理器,它处理关于点或顶点的的几何数据库。这些顶点被连入多边形,通常是三角形。典型的景象有300到30K个多边形,需要每秒处理10K到1M个多边形来实现每秒处理30个框架。最终输出的是一个个的点,通常是每秒输出5百万到一亿个点。我们将我们的讨论范围限制在点的处理内,在我们将有更多的关于几何图形的信息给出。术语十分熟悉附录中,我们将有更多的关于几何图形的信息给出。
在插图1中可以看到3D图像处理流程是由一个应用程序来控制的。通常是通过通知一个API函数来实现的。景象管理在这个应用中可能是完整的,也可能成为API函数下的3D流程的一部分。景象管理传递给3D管道处理器,它处理关于点或顶点的的几何数据库。这些顶点被连入多边形,通常是三角形。典型的景象有300到30K个多边形,需要每秒处理10K到1M个多边形来实现每秒处理30个框架。最终输出的是一个个的点,通常是每秒输出5百万到一亿个点。我们将我们的讨论范围限制在点的处理内,在我们将有更多的关于几何图形的信息给出。术语十分熟悉附录中,我们将有更多的关于几何图形的信息给出。
四、光栅处理
图2描述了一个典型的3D处理数据流。输入时,它接收ransformed,增亮顶点,连接如离散三角形(每个由三个顶点)或三角网孔之类的结构。在一个网孔中,每个新的顶点都定义了一个新的三角形。其余的两个点就是前面的网孔表单中的两个点。最后,流程在CRT屏幕上画图作为输出。图中,圆圈中加个M标出了MMX技术能增强品质或性能的地方。
流程每个顶点包括:
- 视图空间的Y和Z坐标
- R(红),G(绿),B(蓝)色彩元素。可能还包括A(alpha)透明度元素。
- U和V结构坐标(为准备结构化的多边形而设)
其他顶点的特征被典型的包含在一个处理流程的”状态”变量中。在每次一个新的结构,如变暗,混合,变亮等模式被需求时,这些变量必须要明显地变化。典型的状态变量包括:
图2:3D光栅处理.注意:操作顺序可能会有变化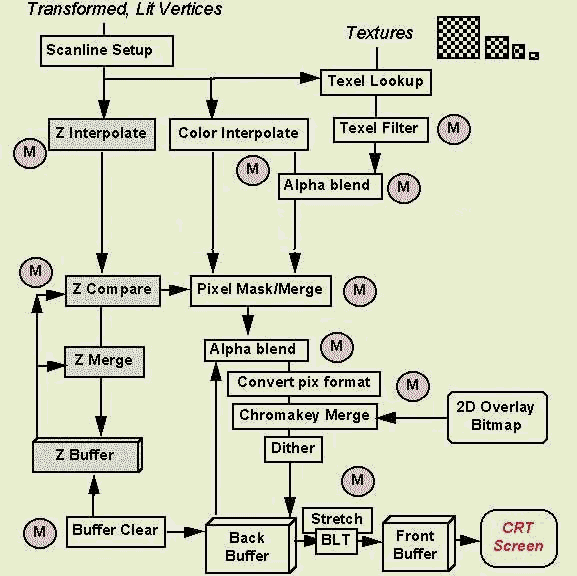
- 结构―如果有的话,是一个指向当前被用来结构化的位图指针结构过滤模式―指针取样,双线性的过滤,MipMapped,等结构应用模式---隐藏,调整,贴画,混合,等
- 阴影模式---平整,Grourand(平滑),拟镜化,或Phong(高亮)
- 材料---决定反光程度
- Z-缓冲---关或开,或是Z-对比的类型
- 裁剪---关或开,变化的类型
- 混合模式---无,有源,目的文件,点画(屏幕通道),等
- 消除走样---关或开
- 抖动---关或开
- 雾化---关或开,与深度的不一致(Z)
为了更加完全地在一个典型的3D库中描述顶点的信息和状态,可查看Microsoft的Direct3D描述。事实上,Direct3D处理管道技术在接下所讨论的步骤中与MMX技术的结合时十分紧密的。而且,我们也希望读者能用Direct3D来实际运用。对顶点的一系列操作时可以变化的,但它的通常模式是:
- 裁剪和精选(移动)多边形---这是对在视图或背景之外的图形采取的操作。从被部分裁剪的图,新的多边形必须以除掉被裁区的地方来建立
- 建立扫描线―一条扫描线是由一系列的水平或y坐标恒定的点组成。通过计算每个角的度数,我们限定每条扫描线的起,终点,以及每条线上点的数目,每个点在r,g,b,u,v,z坐标上的变化。这种细微的变化常称为dr,dg,db,du,dv,dz。
- 建立透视纠正结构―对于结构这样的扫描线附加参数,或是跟小的扫描线的跨度,需要纠正因透视视图带来的前端缩短的影响。没有这样的纠正因数,结构就会扭曲,而且在多边形的边界处会不连续(见图三)
完美的透视纠正需要在每个点上作两次除法,或一次除法加上两次乘法。透视纠正也可不用除法而近似得到。这是通过在每个点上加上du和dv的瞬间变化。这些变化被记为ddu,ddv。在附录中,可参看纠正透视的近似算法。这种算法可以每秒作8或16个点的处罚,或者可以线性插入7或15个点。
- 在扫描线上画每个点。
图3:透视纠正的例子。左边的的有斑纹的立方体没有纠正,在边角处显示出不连续。
 虽然上面建立的运算可以从MMX技术的并行处理中获得益处,但运算的数目是受限的。而且,他们经常是使用浮点运算的。更多的方便将在下面的在扫描献上花每个点的步骤中体现出来。画一个点需要多种运算,依赖于前面讨论过的那些不同的处理方法,处理的顺序可以是变化的,也可以是不完全包括以下内容的,但一般来说,它们是这样的:
虽然上面建立的运算可以从MMX技术的并行处理中获得益处,但运算的数目是受限的。而且,他们经常是使用浮点运算的。更多的方便将在下面的在扫描献上花每个点的步骤中体现出来。画一个点需要多种运算,依赖于前面讨论过的那些不同的处理方法,处理的顺序可以是变化的,也可以是不完全包括以下内容的,但一般来说,它们是这样的:
- 隐藏表面的移动---确定这个点是否被视图中靠近它的其他景象给隐藏。就是说,如果
这个点的z坐标值比与它x,y坐标值相同的已画出的点的z坐标值大,则不要画出这个点。这可通过Z-缓冲或前序排序多边形或扫描线广度来实现。对于Z-缓冲,每个已画好的点的z坐标值必须被重新从缓冲中取出,与新值比较,并根据条件更新。在MMX技术的支持下,一个水平比较和一个集成的与,或操作符可以合并z坐标,就像Intel的Z-缓冲附录中所说的一样。
- 颜色―通过平面阴影或Gouraud阴影和(或)结构映射来计算点的颜色。MMX技术可以Gouraud阴影化2到4个点。每个点上有3到8个记录。可参看附录中的Gourand阴影的像素点填补和单一化的Gouraud
阴影化的文章。
- 结构―查看要映射到当前点的结构元素。如果可以线性或二元线性或三元线性过滤,把它们乘或加起来。如果资源位图是调色板(通常情况),结构化可能需要查看一下为每个texel设计的基于软件的调色板。可能要通过一些统计算法来压缩结构,而且可能要包括Gouraud
阴影化来将基础材料颜色或亮色与结构结合起来。MMX指令还可以总括一个不需要位图资源的结构。这样,者用消耗较少的存储带宽和空间及较少的因放大视图而产生的别名和模块。
- 如果特别的阴影化可行,通过在当前亮度和材料上的值上加或乘,可以高亮一个点。在MMX技术支持下,乘是并不困难的。
- 如果混合可行,将算出的点与图像上早已存在的点混合。PMADD(集成的乘加)指令再一次大大的加快了速度。MMX技术关于alpha-混合的代码可在Interl的网站上找到。同样,雾化效果也可通过简单的乘加混合运算来创建。
- 转化成最终用来显示的像素点格式---在上面的流程中是典型的24位,但在屏幕上显示的是16位。同样,在附录中也有关于将24位转化为16位的最佳方法的篇章。
- 可以抖动一个点的颜色。抖动通常是8位色才需要的,有时16位色也需要。它通过在一种半随机状态下混合一组不同颜色的点来使得一种受限的颜色近似达到更宽广的范围。没有抖动,像天空或日出这样的景色就只能显示出一种“带状”的艺术效果了。
- 复制,或BLT(一列点的模块的转换)使所有的后台缓冲中的图像转换到显示缓冲(或叫前台缓冲)。SW
处理已做好,传到主存或画面外的存储器,并不直接传到最终显示的区域。这就叫双缓冲,使用这种即使是因为直接写到显示区通常比较慢,望前台缓冲里写同样生成图像,因为CRT射线定期刷新屏幕。缓冲的复制或交换通常通过硬件来加速,有时也叫“页置换”。
- 可以伸长,放大,复制像素点。伸长可能出现在前面提到的BLT过程中。附录中关于2x8位图像比例的部分讲了怎么做。它将适应16位获24位的图像。
- 可以用3D图像覆盖或混合2D位图。这种覆盖图在屏幕上产生奇异的图像。通过chromakeying,一些本不应出现的2D矩形位图通常提前被编为一种主要颜色,而且,这种处理器会避免将这种颜色的像素点写入结果。奇异覆盖图的最优代码已经写出了。
- 在画下一个框架前,清空后备缓冲和Z-缓冲。为了消除存储器中的值(比如0或FF),MMX的指令MOVQ用CPU外部总线最大的带宽来写数据(比如,每3个时钟周期8字节就是66MHz,或是在许多奔腾处理器系列中是177MB/S)。注意,后备缓冲和Z-缓冲应该在主存中就为基于SW的处理分配好空间,从CPU进入到PCI存储器是非常慢的。同样要注意,存在不同的方法来避免每次清空整个缓存。比如,后备缓冲就可能通过“脏的数据块”的跟踪来被部分清空。如果软件通过一个精确的四个框架都有的偏移量来更新Z-缓冲,Z-缓冲则只需每四个框架清空一次。
五、像素点色深的转化
8位,16位,24位。MMX技术在16位高彩和24位真彩数据方面作的并不是最好。封装好的加,乘逻辑运算符实际上已使得24位成了最具有吸引力的运算方式。它包含了3个8位(红,绿,兰)元素或?位固定点(48位是给RGB的)。完成运算之后(像Gouraud阴影,alpha,等),算法转化成RGB16(555或565)以来更新缓存。MMX技术并没有内置的算法,也没有为5位而封装的块。24位的内部运算符使得能提供用8位调色板无法得到的高质量的色彩。包括:
- 为雾化,透明化的alpha混合
- 为橙色火光的RGB(多色彩)的光亮,等等
- 拟镜的加亮区
- 瞬间在屏幕上显示多于256种颜色
- 真正平滑的阴影,随意的混合色彩
- 少量(或没有)抖动色彩
- 与其它应用的调色板没有冲突或不协调
- 与高彩的容量和色彩可媲美,接近于HW
加速器
当然,系统的图像存储器的容量决定了是能用16位还是24位彩色。对于1MB的显卡,只能使用8位的调色板(640*480*2
字节需要600KB,如果没有双倍缓冲,或后备缓冲在存储系统中,这只能适应于1MB)。对于2MB或4MB的显卡,16位就很诱人了。640*480双倍缓冲后,占用1.2M,仍留下800KB给字符缓存或Z-缓冲。8位色准许使用一个简单的MOVQ指令来同时以东8个点。如果有了MMX技术的执行单元和“pairing”指令,它也准许16个点的同时比较或(和)混合。不幸的是,8位的调色器处理需要在同一时间内从调色板中读出一个字节。
一直以来,老式处理器的8位处理代码在新的CPU上实际上是扮演着“速度绊脚石”的角色来降低性能。为了奔腾处理器和Dynamic
Execution(TM)处理的高速度,这应被避免。例子如下:
- 自修改代码,它用新的地址或即时值重写了部分指令流。这使得避免使用其它注册者来得到数据。在新的CPU中,每个被修改的指令会浪费许多的时钟周期。因为深层的管道必须被清空,而且缓存必须要重写重取。
- 随机(不是顺序)进入存储区,作为乘法查找的结果,颜色变幻,阴影化或抖动
- 经常的数据独立分支,尤其当他们的顺区不规则时
- 与8位或16位
(AL,AH,AX,BL….)一样,32位的注册是很优秀的,将8位像素点的乘法和简单的32位写或0溢出单独字节结合起来。一次大大的加快了速
|

