Intel
Pentium 4处理器的NetBurst微结构探密
版本1.0
介绍
Intel
NetBurst微结构是Intel
Pentium 4处理器的基础。它包含几个重要的新特性和革新,这些革新与新特性能够让Intel
Pentium 4处理器和未来的IA-32处理器的性能在今后的数年中的处于工业领先的地位。这个文章介绍了Intel
NetBurst微结构中的非常重要的特性和革新。
处理器结构与微结构
一个处理器的结构涉及到向程序员公开的指令集、寄存器和驻留内存的数据结构,这些东西会在一代代的处理器结构中保持并发展。处理器的微结构涉及到硅中的一个处理器结构的实现。在象Intel
IA-32处理器这样的处理器家族中,微结构在实现相同的被公开的处理器结构的换代中做了些代表性的改变。Intel的IA-32结构是基于X86指令集和寄存器的。它是IA-32结构的提高和拓展,它在代码级维持了向后的兼容,这些代码能在早期的IA-32处理器上运行。
如下面的图所示,从发展历史上看,新的微结构需要为典型处理器结构在处理器性能上加强驱动。在时间轴上,每代微结构的生命周期的早期都有很大的性能收益,然而,当微结构设计成熟,性能收益将开始下降,需要新的微结构的发展来继续性能发展在市场上的希望轨迹。Intel的NetBurst微结构是最新的,实现IA-32结构的一代真正的微结构。这个微结构连同一些IA-32结构的拓展的设计,不仅仅是用来增加IA-32处理器的指令处理速度,也是为了获得可视Interet的奇观。Intel的NetBurst微结构允许Pentium
4处理器拥有这个下一代处理器的性能,这样它就能完全地被用户接受,这比只简单关注象文字和电子表格处理这样的应用程序的速度提高要更有意义。这类应用程序只需要保持人能忍受的响应时间的速度就可以了,不象多媒体应用程序需要极大的性能需要。
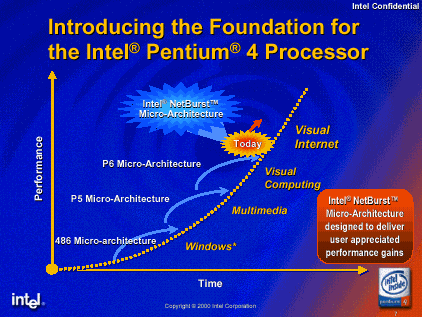
Intel微结构的历史发展和完整的性能轨迹
什么决定真正的处理器性能
真正的衡量性能的唯一的标准是执行给定的应用所花费的总时间。然而大家有一个误解,认为衡量标准是单一的使用时钟频率(MHz)或每个时钟所执行的指令数(IPC)。真正的性能是时钟频率和IPC的混合:
性能=MHz×IPC
这个显示了性能能通过提高频率、IPC或者更好的两者都提高的办法得以改进。它表明频率是制造处理和微结构的函数。在给定的时钟频率下,IPC是处理器微结构和指定执行的应用程序的函数。尽管它对于改进频率和IPC不总是可行的,增强一个而保持另一个可以稳定以前的性能并依然达到可观的高性能。
另外,除了上面谈到的提高性能的两种方法,还可以通过减低执行指定测试任务所花费的指令数提高性能。单指令流多数据流(SIMD)是一个实现这种方法的技术。Intel在1996年的代有MMX技术的Pentium?处理器中第一次引入了64位整数的SIMD指令,随后,在Pentium
III处理器中引入了128位的SIMD单精度浮点(SSE)。
应用程序广义上可以划分为两类,整数/基本办公应用和浮点/多媒体应用。这些不同应用领域的IPC有很大的不同,而这些变化受到了应用代码的分支数目以及对这些分支预测的影响。难以预测的分支越多,错误预测和执行非直接工作的可能性就越高。
整数和基本办公应用,比如文字和电子表格处理,就有很多难以预测的分支存在,因此降低了全部的IPC。因此,这些应用程序的性能提高更多是抵抗微结构的改进,比如加深管道。同样,值得注意这些应用类型的性能上升并不提高用户的使用体验,因为这些应用类型只是需要保持人能忍受的读写响应时间这样的速度,而且当今最高的
Pentium III处理器对这类应用绰绰有余。
浮点和多媒体应用,拥有可预测的分支,自然有较高的IPC潜力。因此,这些应用程序类型在频繁使用的时候一般表现很好,并且也从较深的管道上获得更好的益处。另外,这些应用需要处理器的能力也是极大的:越高的可用性能,用户就有越好的体验。
Intel
Pentium 4 处理器的NetBurst微结构
使用了NetBurst微结构的Pentium
4处理器是一个完全重新设计的处理器,它拥有很多改进了的革新特性的新技术和性能,比如在以前的Intel微结构中介绍的“乱序推测执行”和“超标量执行”。很多这种新的革新和改进使得处理器技术、处理技术和以前不能在高容量中实现的电路设计、可制造方法等方面的改进成为可能。新的微结构的特性和所带来的好处在下面的章节中定义。
为性能的设计
一个受关注的结构的定义的成果被用来研究很多先进的处理器技术的益处和确定未来几年最接近的改进全部处理器的性能。这个定义成果的结果是构造了一个在保持平均大约是P6微结构的10%到20%的IPC的情况下将频率能力从P6的微结构显著地提高40%以上的微结构(在相同的制造处理下)。在这个设计中,尽管IPC比较低,增加了的频率能力弥补了这个(性能=频率×IPC),并将提供给最终用户全面的更高的执行能力。这一切NetBurst微结构利用超级管道技术得以实现,超级管道技术的管道深度是P6微结构的2倍。尽管这个较深的管道提供更高的频率,潜在的与较长的管道有关的性能影响在设计中被包含和克服。这个设计成果的关注点在于:
- 最小化与分支预测有关的损失
分支预测损失的解释:就象P6,NetBurst微结构利用乱序推测执行。处理器一般使用一种分支预测算法来预测程序代码中的分支结果,然后推测性地执行预测出的代码分支。尽管分支预测算法有很高的精确度,但还是不可能达到100%的准确。如果处理器错误预测一个分支,那么所有的推测执行的指令必须从处理器的管道中清除出来以便重新启动程序正确分支的指令执行。更深的管道设计中,更多的指令必须从管道里清除出来,结果是造成分支错误预测出现时有了更长的恢复时间。综合考虑的结果是有更多更难预测的分支的应用程序将使得IPC的平均值更低。
错误预测损失的最小化:为了最小化分支错误预测的损失和最大化平均IPC,深深的管道NetBurst微结构极大地减低了分支错误预测的数目并提供了从任何错误预测分支恢复的快速方法。为了最小化这个损失,NetBurst微结构实现了一个高级动态执行引擎和一个执行跟踪高速缓存。这些特性都将会在本文后面介绍。
- 保持高频率执行单元忙(相对于坐等)
尽管处理器有高频率能力,它必须提供一种方法来确保连续地将要执行的指令提供给执行单元(整数或浮点数)。这确保了这些高频单元执行指令能执行指令(而不是坐等)。用这些在NetBurst微结构中的高频以及快速执行引擎的执行,算术逻辑单元运行于2倍的核心频率,Intel实现了很多能确保这些执行单元获得连续指令流执行的特性。Intel实现了400-MHz系统总线、高级传输高速缓存、执行跟踪高速缓存、高级动态执行引擎和一个低等待1级数据高速缓存。这些特性一起工作为处理器的高兴能执行单元提供指令和数据,从而使他们能够在高频小执行代码而不是空等待。
- 缩减完成一个任务或程序所需要的指令数量
很多应用程序通常在大数据集上执行重复的操作。更进一步,卷入到这些操作中的数据集可以用小量的位来表示成为小的值。这两者的能够结合起来,利用简洁表示的数据集和执行能操作这些简洁的数据集的指令来改进应用程序的性能。这种操作类型称作为单指令多数据(SIMD)并能降低程序执行所需要的指令的整体数量。NetBurst微结构实现了被称作为流SIMD扩展2(SSE2)的144个新SIMD指令。SSE2指令集增强了以前那些利用MMX技术和SSE技术的SIMD指令。这些新指令支持128位的SIMD整数操作和128位SIMD双精度浮点操作。把所给的指令能操作的数据的数量加倍,则只有一半编码循环里的指令需要被执行。
Intel
NetBurst微结构特性细节
超级管道技术:与P6微结构相比,NetBurst微结构的超级管道技术加倍了管道的深度。分支预测/恢复管道这个关键的管道在NetBurst微结构中是用20级的管道实现的,与此相比,在P6微结构中等同的管道只有10级管道。这个技术显著地提高了处理器的性能和基本微结构的频率伸缩性。
执行跟踪高速缓存:执行跟踪高速缓存是一个实现1级指令高速缓存的创新的方法。它存储解码的x86指令(微操作),因此消除了与从主执行循环到指令解码器有关的等待。另外,执行跟踪高速缓存存储这些在程序执行流程路径上的微操作,在代码中的分支结果被综合到高速缓存的相同的行。这增加了高速缓存中的指令流量和更好地使用全局高速缓存空间(12K微操作),因为高速缓存不再存储那些分支过的和永远不会执行的指令。其结果是得到一个传递大容量指令到处理器的执行单元和一个降低从错误预测的分支恢复的全部时间的方法。
快速执行引擎:通过将结构、物理和电路设计的结合,在处理器中的简单的算术逻辑单元(ALUs)运行在2倍的处理器核心频率下。这允许ALUs用核心时钟一半的延迟响应来执行特定的指令从而得到更高的执行吞吐量和降低执行响应延迟。
400MHz系统总线:通过在100MHz时钟系统总线上使用四倍数据传送的物理信号设计和一个允许持续400MHz数据传送的缓冲设计,Pentium
4处理器支持Intel的最高性能桌面系统总线传递每秒3.2GB的数据进出处理器,在Pentium
III处理器的133MHz系统总线下传输是1.06GB/s。
高级动态执行:高级动态执行引擎是一个很深的保持执行单元执行指令的乱序推测执行引擎。它靠提供一个执行单元能选择的很大的指令窗口来实现。大的乱序指令窗口允许处理器消除发生在指令等待相关内容解决时产生的延迟。一个更通用的延迟形式时等待在高速缓存中没有选中的数据从存储器装入。这在高频率设计中时很重要的,因为到主存响应延迟的增加关系到核心频率。NetBurst微结构能有126个以上的指令在这个窗口中,相比较而言P6微结构的窗口就要小很多,它只能有42个指令。
高级动态执行引擎也提高分支预测能力,允许Pentium
4处理器更精确地预测程序分支。相对于P6的处理器分支预测能力,它将大约降低分支错误预测的数量33%以上。它是靠实现一个4KB分支目标缓冲来保存以前分支的更多细节,并实现更高级的分支预测算法来达到上述目标的。这个提高的分支预测的能力是全面降低NetBurst微结构的分支错误预测损失灵敏性的关键设计部件之一。
高级传送高速缓存:2级高级传送高速缓存有256KB大小,有一个在2级高速缓存和处理器核心之间的更高数据吞吐量的通道。高级传送高速缓存由每核心时钟传送数据的256位(32字节)接口组成。作为结果,一个1.4GHz
Pentium 4处理器可以得到一个44.8GB/s(32字节×1(每时钟数据传送)×1.4GHz
= 44.8GB/s)的数据传送速率。和1GHz
Pentium III处理器的16GB/s数据传送率相比,它提供Pentium
4处理器保持高频执行单元执行指令而不是坐等。
流SIMD扩展2(SSE2):作为SSE2的介绍,NetBurst微结构现在通过增加144条新指令扩展SIMD的MMX技术和SSE技术的能力,这144条新指令提供128位SIMD整数算法操作和128位SIMD双精度浮点。这些新的指令提供了降低执行特别程序任务所需要的全部指令数的能力,其结果是提供一个全面的性能提高。它们促进了程序的更广泛的应用范围,包括视频、语言、图象照片处理、加密、金融、工程和科学应用。
综合性能期望
Pentium
4处理器显示了直接改进今天已有的可用软件应用程序的性能,性能水平的改进依赖于应用程序的类别已经应用程序执行指令的趋向还有在新的微结构上优化执行的指令序列。
随时间的过去,更多的应用将被优化,不是特别地为微结构进行汇编级的优化,就是用最新的NetBurst微结构优化编译器和库进行修改,我们甚至将继续看到运行在Pentium
4处理器上的软件更大级别的性能伸缩比例。
总之,依据NetBurst微结构,Pentium
4处理器提供一个在应用程序和使用间的性能的加速度,用户将能真正的体验到和欣赏到。这些应用包括:3D可视化、游戏、视频,语音、图象照片处理、加密、金融、工程和科技应用。
|

